April 07, 2026
toml-spanner: No, we have "Serde" at home
PublishedWith the toml-spanner 1.0 release, it is now a fully featured TOML crate, with deserialization, format-preserving serialization, great error messages, and derive macros. The only thing it's missing is a required dependency of Serde for any of those features.
"Serde" at home:
- (Derive Macro)
Toml: docs.rs/../toml_spanner/derive.Toml.html - (Deserialization)
FromToml: docs.rs/../toml_spanner/trait.FromToml.html - (Serialization)
ToToml: docs.rs/../toml_spanner/trait.ToToml.html
Of course, this isn't Serde at all. It's a derive macro supporting similar features to Serde's, paired with simple traits for converting between TOML and your data types. Let's see how this approach improves things.
Performance: Runtime, Compilation Time & Binary Size
Serde has a reputation for slow compile times and large binaries, but it's actually gotten a lot better over the years. But Serde is fundamentally solving a harder problem: generalized serialization across multiple formats. That added complexity isn't free. Even when the abstractions can theoretically be optimized away, the compiler still has to do the work of optimizing them.
I think the best way to see the cost is just to look at the numbers.
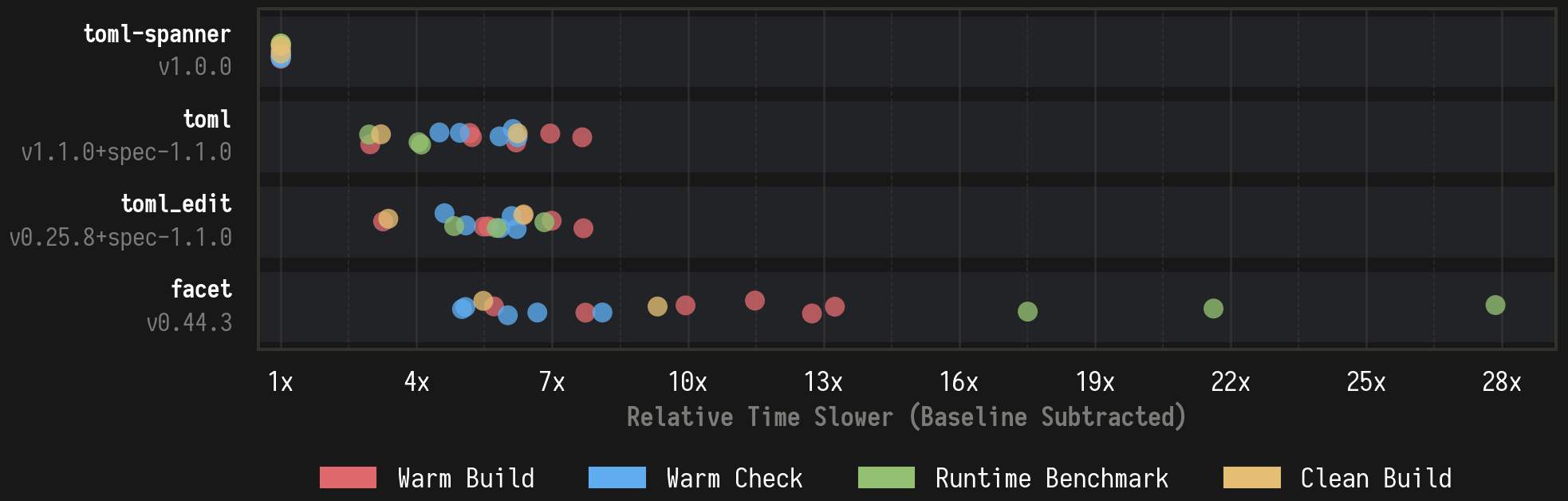
In the above graph, each dot represents a specific type of benchmark, with the value being the mean wall-clock times across samples. The specific benchmarks for that image can be found here: Cargo TOML Deserialization Benchmark Report
Each example application enables the fastest configuration and most minimal feature set needed for each scenario. The Cargo.toml dependency lists and lock file dumps are at the bottom of the above report.
You can find more benchmarks scenarios here:
Incremental Build and Check Cost of Rust Serialization Library Benchmarks
There are a couple of specific benchmarks I want to highlight that I think convey the differences nicely.
Benchmark System Information
rustc: rustc 1.94.1 (e408947bf 2026-03-25) (LLVM 21.1.8)
linker: Wild version 0.8.0
os: Arch Linux (kernel 6.19.9-arch1-1)
cpu: AMD Ryzen 9 5950X 16-Core Processor (32 threads)
memory: 63 GB (3600 MT/s)All benchmarks were performed in tmpfs.
Incremental Warm Check After Prefix Change
This measures the added time each crate contributes to a rustc check invocation by cargo, after a source change earlier in the same compilation unit.
This is particularly relevant for iterative development. Rust-analyzer reruns cargo check after every save, so these numbers directly affect how your IDE feels. The data model here is actually pretty small with only a couple of derives, and these numbers grow as more types are added.
toml-spanner's simple traits allow the derive macros to generate straightforward code that doesn't make rustc do a bunch of work.
Incremental Warm Build After Prefix Change
Same idea, but for a full rustc build invocation rather than just a check. I think it's important to stress what's actually being benchmarked here.
For these Warm Incremental benchmarks, all dependencies and the application are pre-built once, then the raw rustc commands cargo uses are extracted. The source is mutated (here, a "Prefix" change inserting code at the top of the module), rustc is re-run under perf stat. This is repeated a number of times and the mean is taken.
Beyond just perf we can also use rustc's self-profile feature to get more specific information on where time is being spent. Here's an example for same sort of incremental warm build.
label toml toml-spanner
LLVM_module_codegen_emit_obj 243.493ms 18.207ms
LLVM_passes 173.036ms 18.284ms
run_linker 95.897ms 64.159ms
finish_ongoing_codegen 82.820ms 3.335ms
typeck 53.266ms 9.781ms
mir_borrowck 37.305ms 7.573ms
codegen_module 41.248ms 3.364ms
expand_proc_macro 15.270ms 1.861ms
mir_built 11.687ms 3.267ms
metadata_decode_entry_module_children 2.698ms 3.053msNote: These times don't have the baseline (no library) subtracted like the above graph. Interpreting some of the labels does take a bit of effort if your unfamiliarly with rustc internals.
First, expand_proc_macro, which for both toml and toml-spanner takes only a fraction of the overall build time. toml-spanner's takes less time largely due to the smaller amount of code emitted. There are specific optimizations that speed up the actual execution of the macro, but they're not really important in the grand scheme of things.
Frontend wise, the more interesting numbers are typeck and mir_borrowck wise, which take about 5 times longer for toml than toml-spanner. The one reason is the following:
> cargo expand models | wc -l
toml: 7291
toml-spanner: 2282So Serde's derive macros end up generating about 3.2x as much code. Combined with the increased complexity of the traits involved and generics, it's not hard to see where the 5x comes from. When you compare the code-gen between crates, you see very similar approaches. However, Serde ends up needing to duplicate its work to support different formats. For instance, each struct implements both a visit_map and visit_seq.
So far we've only covered the frontend stages for cargo check, but the top 3 slowest things here are backend stages run for cargo build.
Here, toml spends over 10x the time in LLVM. Self-profile doesn't capture metrics internal to LLVM, but we can get some insight by looking at the output of cargo llvm-lines:
First, let's start with the toml crate.
> cargo llvm-lines
Compiling toml_cargo_toml_deser v0.1.0 (/tmp/benchy/toml_cargo_toml_deser)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 2.02s
Lines Copies FunctionName
----- ------ -------------
65352 (100%) 1120 (100%) (TOTAL)
9249 (14.2%) 3 (0.3%) <crate::models::_::<impl Deserialize for crate::models::Package>::deserialize::__Visitor as Visitor>::visit_map
5229 (8.0%) 3 (0.3%) <crate::models::_::<impl Deserialize for crate::models::InheritablePackage>::deserialize::__Visitor as Visitor>::visit_map
4669 (7.1%) 13 (1.2%) <toml::de::deserializer::value::ValueDeserializer as Deserializer>::deserialize_any
4359 (6.7%) 3 (0.3%) <crate::models::_::<impl Deserialize for crate::models::ProfileSettings>::deserialize::__Visitor as Visitor>::visit_map
3621 (5.5%) 3 (0.3%) <crate::models::_::<impl Deserialize for crate::models::Target>::deserialize::__Visitor as Visitor>::visit_map
3078 (4.7%) 3 (0.3%) <crate::models::_::<impl Deserialize for crate::models::CargoToml>::deserialize::__Visitor as Visitor>::visit_map
1797 (2.7%) 3 (0.3%) <crate::models::_::<impl Deserialize for crate::models::Workspace>::deserialize::__Visitor as Visitor>::visit_map
1794 (2.7%) 13 (1.2%) <serde_spanned::de::SpannedDeserializer<T,E> as MapAccess>::next_value_seed
1794 (2.7%) 13 (1.2%) <toml::de::deserializer::table::TableMapAccess as MapAccess>::next_value_seed
1605 (2.5%) 3 (0.3%) <crate::models::_::<impl Deserialize for crate::models::Profiles>::deserialize::__Visitor as Visitor>::visit_map
...Then we can do the same for toml-spanner:
> cargo llvm-lines
Compiling toml_spanner_macros_cargo_toml_deser v0.1.0 (/tmp/benchy/toml_spanner_macros_cargo_toml_deser)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.13s
Lines Copies FunctionName
----- ------ -------------
7792 (100%) 138 (100%) (TOTAL)
1361 (17.5%) 1 (0.7%) crate::models::_::<impl FromToml for crate::models::Package>::from_toml
694 (8.9%) 1 (0.7%) crate::models::_::<impl FromToml for crate::models::InheritablePackage>::from_toml
579 (7.4%) 1 (0.7%) crate::models::_::<impl FromToml for crate::models::CargoToml>::from_toml
569 (7.3%) 1 (0.7%) crate::models::_::<impl FromToml for crate::models::ProfileSettings>::from_toml
495 (6.4%) 1 (0.7%) crate::models::_::<impl FromToml for crate::models::Target>::from_toml
300 (3.9%) 1 (0.7%) crate::models::_::<impl FromToml for crate::models::Workspace>::from_toml
285 (3.7%) 1 (0.7%) core::num::<impl u64>::from_ascii_radix
256 (3.3%) 1 (0.7%) core::ptr::drop_in_place<crate::models::Package>
209 (2.7%) 1 (0.7%) crate::models::_::<impl FromToml for crate::models::Profiles>::from_toml
...From here, it's pretty easy to see why LLVM stages ends up taking over 10x longer. There's nearly 10x as much LLVM IR. LLVM optimizations passes also scale non-linearly with function size, but that's becomes more important in release builds.
But you need to be careful here. Notice the copies column, in toml-spanner each from_toml has a single copy, but in toml the equivalent visit_maps have 3 copies. Digging a little deeper, you can find that it's due to 3 monomorphizations for the following 3 Deserializers:
toml::de::deserializer::table::TableMapAccess
serde_spanned::de::SpannedDeserializer<
toml::de::deserializer::value::ValueDeserializer,
toml::de::error::Error
>
toml_datetime::de::DatetimeDeserializer<toml::de::error::Error>Serde doesn't natively support spans or date-times, so the toml crate hacks around this by wrapping the deserializer in special types like SpannedDeserializer and DatetimeDeserializer.
The problem is that these wrappers show up in the deserialization path for every type, not just the ones that actually need them. Here's one of the clearest examples of how that happens:
fn deserialize_struct<V>(
self,
name: &'static str,
fields: &'static [&'static str],
visitor: V,
) -> Result<V::Value, Error>
where
V: serde_core::de::Visitor<'de>,
{
if serde_spanned::de::is_spanned(name) {
let span = self.span.clone();
return visitor.visit_map(super::SpannedDeserializer::new(self, span));
}
if toml_datetime::de::is_datetime(name) {
if let DeValue::Datetime(d) = self.input {
return visitor.visit_map(DatetimeDeserializer::new(d)).map_err(..)
}
}
.. // truncated for brevity
}We'll talk more about these name-based hacks for span and date-time in their own section, but the important point here is that for every type, even if it's not Spanned or DateTime, these separate monomorphizations are being generated.
One last thing on the generic approach to Serde, which compounds these issues for incremental builds, all this work ends up happening in the crate that uses it. So hiding away your Serde derived types in a separate crate won't help incremental builds unless you put all uses in that same crate. Whereas in toml-spanner all these FromToml impls are completely concrete without generics, so they are just built in the crate there are defined.
Stripped Release Binary Size (added from baseline)
toml-spanner adds only about a quarter as much binary size, saving over 300KB in this example. It's hard to isolate how much of this is from Serde vs other implementation details, but I've found similar savings in past where I migrated other libraries away from Serde.
Clean Release Cargo Build Time
This one isn't just rustc anymore, but instead measures cargo build --release after a cargo clean.
Parallelism becomes a much bigger part of the picture here, which the wall-clock time displayed in the above graph doesn't really capture, so let's look at the perf stat metrics directly:
toml-spanner: 946 ms 7.7 Bcycles 12.55 Binst 1781 task-clock
toml: 3041 ms 41.9 Bcycles 65.11 Binst 9814 task-clock
toml_edit: 3195 ms 51.8 Bcycles 77.47 Binst 12135 task-clock
facet: 5181 ms 92.5 Bcycles 129.94 Binst 21972 task-clockI didn't artificially limit parallelism for these benchmarks, and the test applications are relatively small with narrow dependency trees. This might not be representative of real-world conditions. In CI you might only have access to a single physical core instead of the 16 on my AMD Ryzen 9 5950X. Or you might be building a larger application where the other cores are busy elsewhere.
The task-clock CPU time tells a more complete story. toml takes 3x longer in wall-clock but consumes 5.5x the CPU time. facet is even more extreme: only 5x longer in wall-clock, but over 12x the CPU time.
toml-spanner's simple traits also make manual implementation totally viable:
=== Derived ===
toml-spanner: 946 ms 7.7 Bcycles 12.55 Binst 1781 task-clock
=== Manual ====
toml-spanner: 790 ms 5.9 Bcycles 8.91 Binst 1333 task-clock
toml-span: 921 ms 10.0 Bcycles 14.88 Binst 2271 task-clockEven when deriving, toml-spanner has about the same build times as the original macroless toml-span. And if you consider overall CPU usage, it's actually faster.
Release Runtime Benchmark
Like all benchmarks, take these with a grain of salt. This runtime benchmark uses the same application from the compilation time benchmarks, which (the compilation time) were the actual focus of the benchmark suite.
That said, the results seem reasonable, but unlike the rest of the benchmarks where Serde played a significant role in toml-spanner's advantage, here the story is different. For a format like TOML, Serde's approach should be fairly close to zero-cost at runtime.
Still, I think it's worth noting, even if obvious, that avoiding Serde hasn't hurt runtime performance either.
toml-spanner: 123 ms 0.57 Bcycles 2.10 Binst 123 task-clock
toml: 506 ms 2.29 Bcycles 6.11 Binst 484 task-clock
toml_edit: 842 ms 3.90 Bcycles 10.39 Binst 824 task-clock
facet: 3438 ms 16.24 Bcycles 40.59 Binst 3412 task-clockTo sum up the performance section, toml-spanner would not have been able to meet its incremental compile time goals with Serde.
Serde Data Model Limitations: Date-Times & Spans
Serde doesn't have native support in its data model for TOML's date-time types. To work around this, the toml-rs crates treat them as special structs/fields with magic names like $__toml_private_datetime. This kinda works, but it requires downstream implementers who want to support conversion between these types to be aware of the hack. It also leaks into observable behaviour.
For example, the following valid TOML document gets rejected when parsing into a toml::Table:
foo = { '$__toml_private_datetime' = "bar" }I'm confident this will never be an actual problem in practice. I mostly ran into it while fuzzing against the toml-rs crates.
A similar hack exists for spans. The serde_spanned crate (also maintained by toml-rs) provides a Spanned<T> wrapper that includes byte offsets of values in the source document, using the same kind of magic name pattern ($__serde_spanned_private_Spanned).
Previously, we've seen how these hacks effect compile time but they also have edge cases where they simply don't work, see this issue: Spans, both in Spanned and Errors lost with serde(flatten) / enum variants
When Serde can't stream the deserialization, it converts types into its own private "Content" type first. When that happens, spans are lost, including for errors.
toml-spanner also has a Spanned type, but because FromToml has direct access to span information, no hacks are needed. The same is true for errors, and both enums and flattening preserve spans. This is one of the big bugs that simply disappeared by going our own way.
Spans, Errors and Diagnostics
Beyond just getting spans right, toml-spanner aims to provide the highest quality errors, on the level of diagnostic output you'd expect from a friendly compiler like rustc. To support that, errors carry:
- Primary span: Byte range in the source file
- Secondary spans: Like the first instance of a duplicate key
- TOML paths: Semantic path into the document tree, e.g.
dependencies.toml-spanner.features[0] - Error kinds: For pattern matching and diagnostic leveling
- Developer-specified context tags: For version-dependent behaviour, say deprecation warnings
- Accumulation: Get multiple errors, not just the first one
With Serde, it would be impossible or very difficult to achieve all of these. With our own traits we can design around these requirements and our own derive macros also lets us add attributes for better diagnostics:
const IN_VERSION_2: u32 = 1;
const UNKNOWN_AT_ROOT: u32 = 2;
#[derive(Toml, warn_unknown_fields[UNKNOWN_AT_ROOT])]
struct Foo {
#[toml(deprecated_alias[IN_VERSION_2] = "baz")]
bar: u32,
}The [TAG] values above are optional tags you can attach to diagnostic attributes. This allows for easy programmatic filtering and annotating later on.
So if you parsed this input to Foo:
baz = 32
extra = "text"You'd get two non-fatal diagnostic errors like:
Error {
kind: Deprecated,
tag: IN_VERSION_2,
message: "key 'baz' is deprecated, use 'bar' instead",
span: 1..4,
path: Some("baz"),
}
Error {
kind: UnexpectedKey,
tag: UNKNOWN_AT_ROOT,
message: "unexpected key",
span: 9..14,
path: Some("extra"),
}Then the Error type has methods that make it easy to integrate with diagnostics crates like annotated-snippets, giving you output like:

Derive Macros
Continuing on improvements to derive macros, toml-spanner can add format-specific attributes that wouldn't make sense for general frameworks like Serde. For instance, a style attribute that controls how a value is serialized to TOML:
use toml_spanner::Toml;
#[derive(Toml)]
#[toml(ToToml)]
struct Value<'a> {
name: &'a str,
#[toml(default = false, skip_if = |&value| value == true)]
enabled: bool,
}
#[derive(Toml)]
#[toml(ToToml)]
struct Config<'a> {
#[toml(style = Inline)]
alpha: Value<'a>,
#[toml(style = Dotted)]
beta: Value<'a>,
#[toml(style = Header)]
entries: Vec<HashMap<&'a str, u32>>,
}Note: toml-spanner breaks from the convention of forcing all attribute values to be strings. This allows for some level of IDE integration, such hovering on these style values to see documentation.
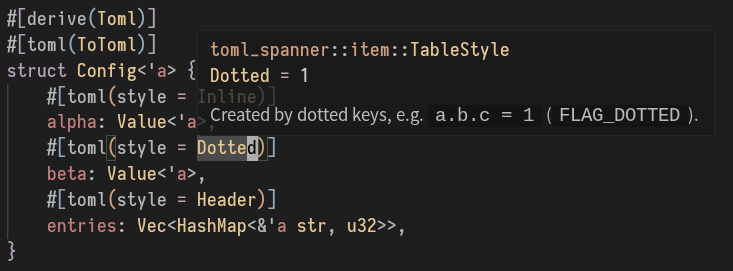
If you then serialized something like:
let config = Config {
alpha: Value { name: "alpha", enabled: true },
beta: Value { name: "beta", enabled: false },
entries: vec![
HashMap::from([("foo", 1), ("bar", 2)]),
HashMap::from([("baz", 3)]),
],
};
println!("{}", toml_spanner::to_string(&config).unwrap());You'd get:
alpha = { name = "alpha" }
beta.name = "beta"
beta.enabled = false
[[entries]]
foo = 1
bar = 2
[[entries]]
baz = 3Manual Implementations
Serde's complex traits make manual implementation something you actively want to avoid. toml-spanner started as a fork of toml-span, which was designed not to need derive macros at all. toml-spanner has kept those same capabilities, with slight adjustments for performance.
struct Foo<'a> {
a: u32,
b: &'a str,
}
impl<'de> FromToml<'de> for Foo<'de> {
fn from_toml(ctx: &mut Context<'de>, item: &Item<'de>) -> Result<Foo<'de>, Failed> {
let mut helper = item.table_helper(ctx)?;
let foo = Foo {
a: helper.optional("a").unwrap_or(32),
b: helper.required("b")?,
};
helper.require_empty()?;
Ok(foo)
}
}I typed the above from memory into the markdown, with zero auto-complete. That should give you a sense of the simplicity.
The equivalent using the derive macro:
#[derive(Toml)]
#[toml(deny_unknown_fields)]
struct Foo<'a> {
#[toml(default = 32)]
a: u32,
b: &'a str
}The Toml derive macro is quite powerful and supports most of what Serde supports: See Docs
But if you need a manual implementation, it's not a big deal. It's reasonable to just manually implement everything and do away with derive macros altogether, as all the users of toml-span already do.
Of course, it's not impossible to implement Serde impls manually either, but it's not trivial. There are ways to build helpers to bridge that gap in Serde, but it's not without costs.
Take serde_untagged, which Cargo uses for a number of manual deserialization impls in cargo.toml manifests.
> cargo llvm-lines --release --lib | head -4
Compiling cargo v0.97.0 (/home/user/git/cargo)
Finished `release` profile [optimized] target(s) in 50.14s
Lines Copies FunctionName
----- ------ -------------
4102515 (100%) 82526 (100%) (TOTAL)
119978 (2.9%) 82 (0.1%) serde_untagged::int::<impl serde_untagged::UntaggedEnumVisitor<Value>>::dispatch_integerLooking at cargo llvm-lines for Cargo's release build, this one helper crate alone generates 120K lines of LLVM IR, which is a lot. The additional abstractions layered on top of the existing abstractions seem to compound the bloat even more.
Because toml-spanner's traits are simple without all these layers of abstraction, there's no need for a crate like serde_untagged.
Benefits of Serde
So far I've mostly talked about what toml-spanner gains by avoiding Serde but like everything there's trade offs and by going it's own it loses out on:
- Reusing the ecosystem's existing Serialize/Deserialize implementations
- Serde's extensibility through middleware (things like serde_ignored)
- Familiarity
Now, there are other costs too, but not in the same way. Writing your own derive macros isn't free. Proc-macros are hard to test and the type system doesn't help you the way normal Rust code does. Serde's derive macros have had years of bug fixes, performance tuning, and battle testing across tens of thousands of applications. toml-spanner's almost certainly have a couple of rough edges that will need sanded down as new users test in ways I haven't imagined. In my case, I had already written feature-rich, high-performance derive macros for Jsony, which just needed a little adjusting for toml-spanner, so I had a head start.
toml-spanner is really targeting the application config use case, and I think I've covered the needs of most apps here, so that the extensibility lost from the simpler traits isn't as much as a downside. For instance, cargo uses serde_ignored to capture unused keys with full paths. However, toml-spanner's multi-error accumulation combined with the TOML paths included in errors already solves that use case in a cleaner, more performant way.
Another potential benefit of using Serde is that its traits enforce correctness through the type system, making it harder for manual impls to do something wrong with the parser. This matters more for streaming formats, but TOML's out of order nature means you need an intermediate tree anyway. toml-spanner's FromToml and ToToml traits work with Item conversions rather than directly with a parser, so you get the same kind of typed correctness properties. I mention it here because Jsony has this problem (see jsony::FromJson).
The loss of familiarity is a real cost. I could have made toml-spanner's derive macros much closer to Serde's by using the exact same attribute names and format. That would have softened the learning curve, but it also would have meant giving up places where I think the attributes can genuinely do better. I chose the improvements over familiarity.
The unavoidable cost is the ecosystem's existing support for Serde combined with Rust's orphan rules. That's mitigated, to some extent, by the derive macros' with attribute and the simplicity of the traits.
"Serde" at Home
The "Serde" at home approach turned out pretty well. Faster compiles, smaller binaries, spans that don't break, and error diagnostics that wouldn't have been possible through Serde. There are real costs to going your own way, but for toml-spanner the trade-off was worth it.
There are already great Serde-based TOML crates and they're the right choice for a lot of projects. But if compile times, binary size, or diagnostics matter to you, toml-spanner is worth a look.
Project Git Repository: https://github.com/exrok/toml-spanner
API Documentation: https://docs.rs/toml-spanner/latest/toml_spanner/